All's Well that Ends Well, and Why Put a Grid behind Your Spreadsheet in the First Place

A
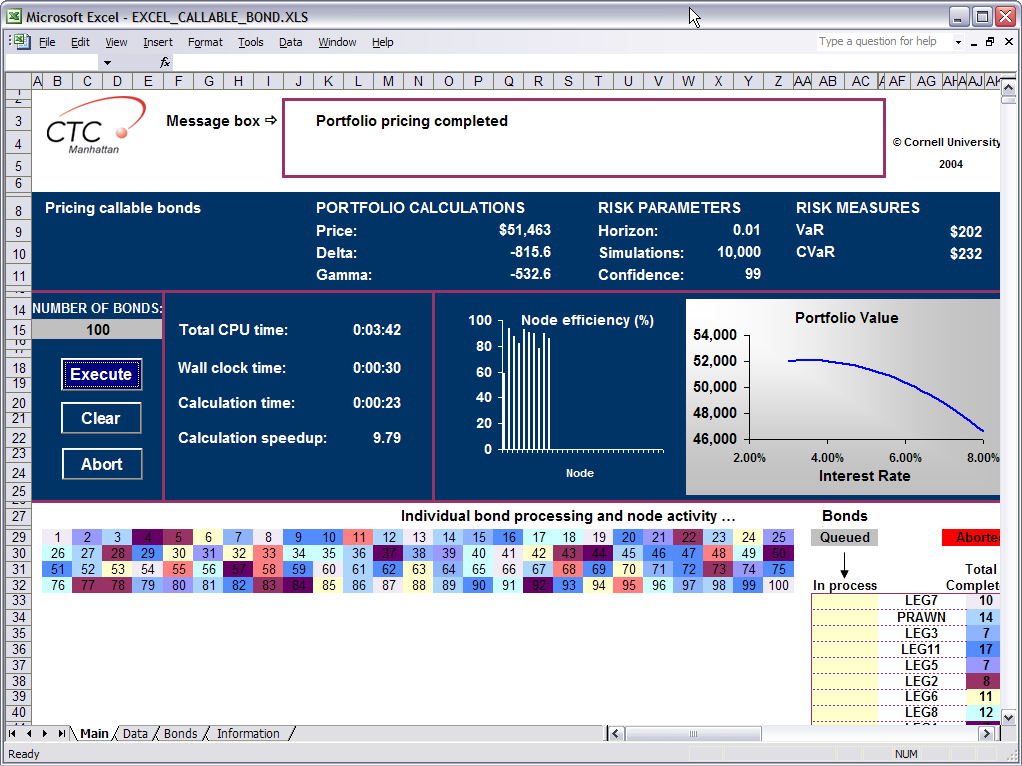
ll's well that ends well, said Wm. Shakespeare, and I'm pretty sure that if he were around today he would have agreed that my Excel Services demo ended well. For those of you who have followed my continuing series, I had a sometimes-difficult but always-interesting time taking an interactive spreadsheet with .NET code behind and porting it to an Excel Services spreadsheet with a managed UDF.In the end, the spreadsheet looked great, the UDF was easy to run on a grid (or cluster), and we got a snazzy looking demo out of it (not to mention terrific use of our own product).
But the question is: why do you need to put a grid behind Excel Services in the first place?
Well, there are a couple of reasons. First, you may simply have something that can be broken up and run faster. In the sample I did, the UDF (User Defined Function) was pricing bonds for different interest rates--each bond takes somewhere between 1 and 5 seconds to price. Because each bond can be priced individually, they can be done in parallel. I simply wrote a class that prices one bond, then I instantiated one object for each bond I needed to price and the Digipede Network took care of executing them in parallel. On my cluster of 10 machines I routinely saw a speedup of at least a factor of 10 (a couple of my machines are dual proc, so they were shouldering twice the load of the other machines).
But there's another, more broadly applicable reason: moving compute load off of your SharePoint server.
Excel Services and SharePoint Server do a wonderful thing: they make it really easy to make powerful spreadsheets accessible to many people. It's the same conundrum we see in SOA and in SaaS: if you make something available as a service, you subject yourself to widely varied levels of usage. What happens if many people use that service at the same time?
Imagine this scenario: A developer in a brokerage house has written a spreadsheet that has a really cool UDF: the user types in an account number, and the UDF calls up the portfolio for that account, then does an optimization on that portfolio, then Excel Services renders a spreadsheet with numbers, charts, etc. The whole thing runs for about 20 seconds.
That spreadsheet is published up to the SharePoint server so all of the brokers in the firm can access it when their customers call. This all sounds great so far--but then the brokers start using it.
All of a sudden you have many portfolio optimizations running on the SharePoint server simultaneously. Everything slows down, and everyone's frustrated. In addition to the normal load that the SharePoint server is running, it is now running 20 seconds of portfolio optimization for each render of that spreadsheet. Performance for the entire system goes downhill.
Now, imagine taking that code in the UDF and running it on the Digipede Network. Simply by adding about 20 lines of code, that UDF calculation can run on a cluster (or grid) instead of on the SharePoint server. It lets the SharePoint server keep doing what it's doing (serving web pages, running Excel Services), moves the compute-intensive process onto a cluster or grid, and thus creates a very scalable solution.
Bear in mind, this doesn't involve "breaking up" your UDF or figuring out how to parallelize your code: each UDF call is running on one machine. But many UDF calls are running in parallel on different machines.
 It's very similar to what I wrote in February about web services. When you make something available as a service, you need to be prepared to address the scalability issues involved.
It's very similar to what I wrote in February about web services. When you make something available as a service, you need to be prepared to address the scalability issues involved. It all adds up: Digipede + Excel Services UDFs = Crazy Delicious